HW0: Introduction
I am Jack Fraser, a Senior in Computer Science at the College of Charleston. This semester (Fall 2019) will see many posts to this blog for assignments for this CSCI 362 - Software Engineering.
Blog Posts for this class will be titled with “HWX: Title”, and will focus on answering and responding to questions and articles with a Software Engineering focus. The earlier of these were originally uploaded to Wordpress. The later (4+) are published exclusively to this quintuplin.github.io
This blog, however, does include posts not for this class; Some are from CSCI 392, and others (yet to be written) will hopefully punctuate an illustrious career within CS.
My hobbies include trying to utilize WSL for intended-for-full-linux applications, making .exes in Python, and utilizing vscode religiously. I have an irrational dislike of Java, and pretend to like C despite actually being rather scared of it. Nonetheless, my next target language to learn is c++, especially when accounting for its versatility and power when it comes to user interfaces. The Visual Studio XAML Designer is just too tempting.
I am happily married, and spend way too much time daydreaming about video games.
Welcome.
HW1: Chapter 1
Global 1.3: Briefly discuss why it is usually cheaper in the long run to use software engineering methods and techniques for software systems.
Because Software Engineering methods are thorough, they increase the initial cost/time/effort when creating a new project. However, the same methods lead to a stronger foundation, making software which is easier to support, modify, or expand upon; more approachable for new programmers to come in and be able to understand due to a concrete design process having been used; more accessible to users (or auditors) due to the extensive documentation; and generally more thoroughly tested. While it is possible (especially in smaller projects) for a rogue software to reach all of the targets (acceptability, dependability, security, efficiency, maintainability), software engineering does a lot to ensure and standardize reaching each of these goals, and is essential for larger projects where no amount of ‘good practice’ can outweigh sheer size and complexity.
Proper 1.3: What are the four important attributes that all professional software should possess? Suggest four other attributes that may sometimes be significant.
The “figure 1.2” attributes are Acceptability, Dependability (and security), Efficiency, and Maintainability. For my 4, I would formally declare Security independently, as well as add Readability, Reusability (as a component in future projects), and Moddability (flexibility to have new features added). All of these (with the exception of Security), could be defined as a subset of the first 4 core attributes.
Global 1.8: Non Certified individuals are still allowed to practice software engineering. Discuss some of the possible drawbacks of this.
Misapplication of Software Engineering processes are, at best, ineffective for what they’re designed for, and a waste of resources. However, at worst, they can be downright counterproductive, create unnecessary confusion, or make otherwise simple code extremely complex as the confused programmer attempts to shoehorn in practices where they do not belong.
Proper 1.8: Discuss whether professional engineers should be licensed in the same way as doctors or lawyers.
Licensing is beneficial because it
Can be used to improve one’s resume Represents a useful and non-standard skillset Can be done incorrectly by a non-certified individual Is important enough to be done by a certified individual Licensing ‘in the same way as doctors and lawyers’ is ridiculous, however, because medical school and law school both take wasteful amounts of time and money to complete; this is an important skill, but not one that requires a doctorate to be able to practice it. A certification system, therefore, seems like a much better fit.
1.9: For each of the clauses in the ACM/IEEE Code of Ethics shown in Figure 1.4, propose an appropriate example that illustrates that clause.
Act in the Public Interest: If the software is in a high-stakes field (e.g. medical), one must prioritize testing to ensure that there are no failure states for the code; If management wants to release an incomplete product, one should engage in whatever is necessary (within legality) to stop it from being released irresponsibly. An example would be a heart monitor software that has a chance to crash. If management tries to release it, raise the issue (with documentation of your efforts), first to management, then to their bosses, then to legal team, then to the ceo, and finally to news; such a situation can not be allowed to ‘sneak into’ the industry and kill real world people due to unchecked corporate greed.
Client and Employer: One should always engage in good faith, and work toward what the client’s goals are, not what they should be. However, this does not excuse working on an unethical project. An example would be if you work at a facial recognition company who decides to start selling their software to ICE. That’s unethical, and you shouldn’t work there.
Product Professional Standards: One should never release code which is incomplete or not up to personal quality expectations. An example would be a project that is not life-threatening to release early, but still definitely not ready; don’t let management push it out the door without at least some documentation of your disagreement, but don’t take it as far as a public issue.
Integrity of Judgement: One should attempt to retain scientific detachment, especially when testing/bug fixing code, or hearing feedback; the software comes first, not one’s own emotions. An example is if you’re trying to get feedback on your prototype: you have to be detached enough to listen when a user insults every single element of your design, no matter how attached you are to it, because it’s valid. Some of that feedback might not be actionable; some of it will: your job is to improve what you can, and remember the rest for the next project. There is always room for improvement.
Ethical Management: Managers should be ethical; if they aren’t, you probably don’t want to work for them. As an example, if your manager doesn’t listen in an ethical issue scenario (e.g. the public issue at the top of this list), you definitely don’t want to be working under them. They’ll probably try to blame it on you if something goes wrong anyways, so do keep documentation of everything.
Advance the Profession: It’s your job to make your job look good. (To me, this one is more a ‘strategy for success’, less an ‘ethics’ item. It’s odd to include it here.) For example… if your boss asks what you’ve been doing, try to represent the industry well: work hard, have a lot to show, and make sure it improves on the actual business at hand, rather than just offers an alternative.
Colleagues: Be nice to them. For example, if you have a colleague, be polite to them, and listen to their suggestions.
Self: work to always improve, while retaining ethics. For example, nearly every year, something is released that fundamentally changes (and improves) some process of software development, website design, or programming in general. Keeping up with new frameworks is a full time job, but it keeps you relevant in this ridiculously quickly evolving industry.
Global 1.10: The “Drone Revolution” is currently being debated and discussed all over the world. Drones are unmanned flying machines that are built and equipped with various kinds of software systems that allow them to see, hear, and act. Discuss some of the societal challenges of building such kinds of systems.
Drones are a simple example of a technology which the current laws and rules of society simply weren’t designed for. When scaled to their logical conclusion, we’re facing a perfect information system; a surveillance state of unprecedented power, accessibility, and affordability. Ignoring the issues with governments having access to this kind of information – what of neighbors? Corporations?
Privacy becomes unenforceable, and mapping out an individual’s activities, location, or patterns is the first step in any targeted malicious act. Imaging a robbing crew that knows where everyone is at all times: perfect stealth, without having to post a watch? Nah, that’s small-time stuff. Let’s go bigger. Scale it to a national level; automate the data collection, and put some hefty data science to analyze it all in real time. Unified databases with complete activity tracking of the entire population.
Then look at the technologies that such information enables. Try an electronic billboard that displays individually targeted advertisements to people as they go by; ads that are tailored by tracking their actual physical responses to viewing them: a sufficiently advanced system down that path could effectively control an individual, not with a single advertisement, but with a sequence of clever manipulations that lead, inevitably, to a product … or a candidate. And what use is democracy, if the population itself is compromised?
Drones themselves might be merely the beginning; but they are the beginning of something that will be very difficult to put back into the bottle.
Nonetheless, progress cannot be stopped; we must engage carefully (and with regulation as needed), in order to explore the possible positive futures, while safeguarding against the negative ones. It’s a scary world out there, but any technology can have a positive impact if done right; drones (and perfect information systems) included.
Proper 1.10: To help counter terrorism, many countries are planning or have developed computer systems that track large numbers of their citizens and their actions. Clearly, this has privacy implications. Discuss the ethics of working on the development of this type of system.
The ethics of such a system are complex to say the least. On the one hand, a technologically feasible system which can save lives could be construed as ‘killing people by not being made’. If a global catastrophe would have been preventable with such technology, but wasn’t, then that falls on the ethical heads of anyone who opposes it.
On the other hand, creating a perfect information system has more than a few misuses. When ‘a government’ has access to that kind of power, what it really means is that ‘the people who work in government’ have access to that power; and people are people. People are selfish, greedy, have prejudices, are susceptible to religious fervor, and similarly susceptible to manipulation. Systems are hackable. Someone getting access to the wrong information could allow horrible crimes to be committed; somebody modifying the data within a ‘perfect’ system could allow a hacker to make anyone they want to a target of world governments. Too consolidated an information system, without the social structures in place to limit and manage it’s potential, does far more harm than good.
For now, I think that we are not ready for a system such as this. But the upsides of one done correctly are meaningful, and I would like Humanity to move towards being ready for such applications of technology. After all, they’re coming whether we’re ready or not, so we have to try to do it right the first time before it’s too late.
HW2: Responses
- http://cs.cofc.edu/~bowring/classes/csci%20362/docs/NoSilverBulletOriginal.pdf
- http://cs.cofc.edu/~bowring/classes/csci%20362/docs/p32-neville-neil.pdf
- http://cs.cofc.edu/~bowring/classes/csci%20362/docs/GoogleCodeRepo-78-potvin.pdf?id=0B2El51RQ1MQnTTVWYVNiOWhuX0U
A response to Silver Bullet, Cherry Picking, and Google Code Repo:
No Silver Bullet seems to believe that large-scale coding will always be difficult, and that there are no easy solutions to this. It’s pretty outdated, although while version-control and automated testing have changed, many of the fundamentals of software engineering haven’t. Nonetheless, it seems to have been almost completely disproved by first git, then Google’s versioning control system, in which a massively automated super-git-like-repository allows users to add code, test it, and incorporate it into the main program structure with extreme ease; all despite the ridiculous scale of their combined projects. Perhaps there is a silver bullet after all.
Cherry Picking, meanwhile, speaks of how difficult it can be to determine what code should be taken from a branch, and why; while also giving some recommendations on how to effectively find (and fix) bugs in a responsible, scientific, and documentation-heavy manner. It brings up many valid points about how tricky excessive branches can end up being. Again, this lends even more credibility to Google’s own no-branch system.
Finally, Google Code Repo, which really just made me super envious of having such a talented and dedicated support team to create and maintain such a glorious beast of a version control system. It’s pretty spectacular, and really makes me appreciate just how much Google has legitimately achieved despite (or perhaps because of) their occasional ruthless business move.
Really, all three articles just make me want to use Google’s system for… everything? Maybe someday we’ll get enough people to leave Google over ethical issues that they can form their own version control company, and make a rival to git.
HW3: Chapter 10
10.6 Explain why it is reasonable to assume that the use of dependable processes will lead to the creation of dependable software.
The dependable process ensures the creation of code which is reliable, resistant to failure, and stable by ensuring that a number of sub qualities are achieved; each with concrete goals and positive outcomes. While it is a specialized process, it is one that is well suited to the title ‘dependable’.
Auditable – something all code should absolutely be; When a system is making judgments that can drastically alter a person’s life, such as a facial recognition system used on security footage of a crime scene, or a heart monitor determining if the heart has stopped or not; it is absolutely important to be able to clearly determine if that code is done correctly by as many individuals, from as many backgrounds as possible. One can not simply ‘be confident’ in systems that are important enough.
Diverse – even within this chapter, diverse code is argued to be unnecessary if the standard logic is sufficiently tested and vetted; nonetheless, if your software requires redundancies, those redundancies should not fail in the exact same way that the main cycle failed; otherwise, what’s the point in having redundancies at all? Diversity is the only way to implement redundancy properly, so it belongs here, because it makes code, not more efficient, but more dependable. Which is the whole point of this process, after all.
Documentable – All code should be documented. Better documentation means easier to use correctly, and easier to read/modify the code as needed. Documentability just makes making good documentation itself easier; so it’s a good trait.
Robust – A recoverable error should allow the software to keep going? Sounds like excellent software design, especially for a software that one must depend upon to work under all conditions.
Standardized – why reinvent the wheel (and force yourself to reinvent every wheel afterwards), when you want it to work reliably? Innovation is for cutting-edge systems and hacky scripts, not dependable software.
In summary, all of these traits make code more dependable, and as such, are well suited to belong in a feature list of a ‘dependable’ process. Code made using the dependable process would almost certainly be more dependable than code not made using the dependable process. Therefore, the dependable process makes dependable code.
Other 10.6 A multimedia virtual museum system offering virtual experiences of ancient Greece is to be developed for a consortium of European museums. The system should provide users with the facility to view 3-D models of ancient Greece through a standard web browser and should also support an immersive virtual reality experience. What political and organizational difficulties might arise when the system is installed in the museums that make up the consortium?
Such a system sounds primarily to involve issues regarding policy, and technical specifications. Politics and organization are much harder to visualize. However, museums rely on visitors, so in that manner, a virtual reality system might threaten their primary source of income. Meanwhile, doing it poorly might harm them even more. So they must make a good one, which requires resources, but museums are not extremely wealthy, so this is a no-win scenario. The only upside to this is to share art with the people who cannot make it to the museum, for the pure purpose of education. However, this might cause the museum to rely more heavily on public funding in order to stay afloat. Inversely, such a technology might increase interest in the member museums, making tourism rise. The political issues, therefore, might be those of conflicting forces wanting to minimize risks, maximize educational opportunities, minimize costs, and potentially want to properly invest in a future income opportunity. Since any angle could be effectively argued, and because museums are frequently the beneficiaries of public funding, politics will most definitely come into play when determining policies that would directly affect the availability or feature set of the virtual reality experience.
Another potential ‘political’ issue would be if an artist featured in the museum doesn’t want to be featured in the virtual reality museum; because software and physical museums are under different regulations, they might have that right; straining the organizational parameters of the project (display this but not that, somehow still make the museum not look empty in the virtual space) due to the impact of a political situation.
Organizationally, the software needs to be usable in both web-based and vr systems. These are two extremely different platforms, so much so that two completely different softwares under the same name might be the only sane route for attempting this. They will need different levels of details, or even completely different types of access (web-based being, potentially, more web-cam style, whereas the vr system could use a virtual museum with high resolution 3-d scans of the artwork). These are primarily technical and design issues, however. Organization would mostly involve keeping the two projects (vr and web) aligned design and feature-wise.
10.10 It has been suggested that the need for regulation inhibits innovation and that regulators force the use of older methods of systems development that have been used on other systems. Discuss whether or not you think this is true and the desirability of regulators imposing their views on what methods should be used.
Regulation is a necessary part of becoming a valid industry; we shouldn’t be the wild west when our systems are used in life-saving or potentially life-ending technologies. Ultimately, any issue with the regulation process requires reform within that process.
Leaving any industry to self-regulation has time and time again proven to be ineffective and unacceptable. It is simply too tempting to cut a corner that ‘no one will see’, especially when business people are making the decisions; someone can always be found to do a dirty job, and innocents (and customers) are the first to be hurt.
It doesn’t really matter how behind the times a regulator’s practices are; they’re in place because an expert placed them there; it could be for a very good reason. And even if they aren’t, at least the baseline exists at all.
Other 10.10 You are an engineer involved in the development of a financial system. During installation, you discover that this system will make a significant number of people redundant. The people in the environment deny you access to essential information to complete the system installation. To what extent should you, as a systems engineer, become involved in this situation? Is it your professional responsibility to complete the installation as contracted? Should you simply abandon the work until the procuring organization has sorted out the problem?
Jobs being made redundant to automation is an unavoidable result of this line of work. Some might even say a goal. Hopefully, those individuals can be reallocated to new positions which have been made possible due to the money saved in their own (former) department. It should be the imperative of employers (and governments) to reinvest funds saved by proper application of technology, not just for moral grounds, but to avoid wasting those resources entirely. CEOs don’t need a pat on the back, a windfall bonus check, and a cookie for managing to make their company up to date technologically; they need to continue to move forwards.
Ultimately this is a systemic issue. We are inevitably automating away every job; even our own. A global long-term solution needs to be found; but progress is progress. Coal mining is no longer a job that anyone should be in; it’s a dead industry, and we shouldn’t artificially keep it alive when doing so costs us investing in future-proof solutions (such as solar), which provide a greater net positive for humanity and create jobs in new places. In the same way, we must look forwards, rather than cling to the past.
However, being denied the resources necessary to complete a job might mean that your employer is unworkable. Put it in writing (in no uncertain terms) how essential their cooperation is for the project to move forward. Document everything. Raise alarm with the bosses. If nothing can be done, make it clear the project will have to be cancelled. There should be stipulations in your contract for such a contingency. Hopefully it won’t come to that, but ultimately if you cannot complete your job properly, you cannot complete your job.
HW4: Chapters 11 & 12
11.4. What is the common characteristic of all architectural styles that are geared to supporting software fault tolerance?
Diversity. This is due to the logic that a redundant/diverse system will be able to survive one portion failing, by having a fallback which can take the same input without failing in the same way. These are often designed with multiple layers or types of structure behind the diversity, such as n-version, three-channel, etc. Diversity is the best way (after writing good code) to improve a software’s ability to function reliably despite faults.
11.7. It has been suggested that the control software for a radiation therapy machine, used to treat patients with cancer, should be implemented using N-version programming. Comment on whether or not you think this is a good suggestion.
N-versioning essentially means that there is some number N such that that number of completely independent versions of the target specifications are created, then run concurrently, with an overseer which determines which one is most correct on output. The upsides of such a design is that any individual failure on any individual version can be ignored or outvoted by the other versions. Also, since they are generally diverse, it is unlikely that they all fail in the exact same manner, reducing the likelihood of having a complete failure.
However, the downsides are that the resources for development need to be split among parallel development teams; 3 bad systems doing the same thing as 1 good system could mean that the correct result gets outvoted, rather than the other way around. Similarly, 3 good systems simply means that 1/3 of the total progress on the project has been achieved, and the hardware costs to support the triply developed software means that costs stay higher in the long run.
This type of system is essential for softwares which can harm significant numbers of people on failure; airplanes and nuclear power plants being a perfect example. However, a radiation therapy machine may or may not be at the same scale. One could argue that, if a large number of hospitals buy the machine, a large number of patients utilize the machine before a fault is discovered, and the fault leads to death, then it would globally cause more harm than a single airplane failure, which generally only has to crash once or twice before the product line is pulled and fixed. From this perspective, the radiation therapy machine absolutely requires n-version programming – more so than ‘more visible’ systems like airplanes.
11.9 Explain why you should explicitly handle all exceptions in a system that is intended to have a high level of availability.
Exceptions are the most easily quantified and fixed bugs; they have custom error messages in most languages, and are easily detected and fixed for that very reason. Because of this, there is basically no excuse for not handling exceptions properly. They can make recovering from certain faults (especially data type faults) extremely easy, and explicitly defining the course of action to the software for each type of fault in each possible context is a very solid manner of making your software resistant to common issues.
12.5. A train protection system automatically applies the brakes of a train if the speed limit for a segment of track is exceeded, or if the train enters a track segment that is currently signaled with a red light (i.e., the segment should not be entered). There are two critical-safety requirements for this train protection system:
1: The train shall not enter a segment of track that is signaled with a red light.
2: The train shall not exceed the specified speed limit for a section of track.
Assuming that the signal status and the speed limit for the track segment are transmitted to on-board software on the train before it enters the track segment, propose five possible functional system requirements for the onboard software that may be generated from the system safety requirements.
- The system must have redundant sensors and diverse signal interpretation, so that an error cannot prevent the train from receiving the speed/signal status
- The system must have some detection (sensors + analysis) for track conditions, in case of ice/snow/rain which would lower the safe speed of train operation below the local speed limit
- The system needs safe, reliable default values in case of being unable to receive the speed limit of the next track segment.
- The system needs to stop the train (assume red light) in case of being unable to receive the ‘red light’ status of the next track segment.
- The system needs access to emergency brakes and sensors in place to engage them in order to prevent a head-on collision in case of detecting something on the tracks
- The system needs to handle speed changes such that when raising the speed limit, the train does not accelerate before crossing into the new segment; but when lowering the speed limit, the train has decelerated to the new limit before crossing into the new segment.
- The system needs tracking of the status of hardware (especially battery, fuel, engine functions, brake functions, sensors, etc.); it must alert management when components are worn down or when it has reached a recommended maintenance stage, and give severe warnings (including refusing to embark) in case of essential components not responding to the system/ responding as broken.
- The system needs a method of communicating with the outside world in order to give live updating of any issues that may occur;
- The system must be able to receive an ’emergency stop’ command from outside (including from other trains)
- If the train stops for any reason, it must broadcast an ’emergency stop’ command to the nearby track to prevent other trains from potentially crashing into it the system should have verbose logging in case of audit / error
HW5: Reflections
- http://cs.cofc.edu/~bowring/classes/csci%20362/docs/Therac25Accidents.html
- http://cs.cofc.edu/~bowring/classes/csci%20362/docs/The%20Radiation%20Boom%20-%20After%20Stroke%20Scans,%20Patients%20Face%20Serious%20Health%20Risks%20-%20NYTimes.com.pdf
- https://www.ic3.gov/media/2016/160317.aspx
- http://cs.cofc.edu/~bowring/classes/csci%20362/docs/levesonSoftwareAccidentsSpacecraft.pdf
- http://cs.cofc.edu/~bowring/classes/csci%20362/docs/SpectrumFBIcaseFileSytem.pdf
- http://www.washingtonpost.com/wp-dyn/content/article/2010/10/20/AR2010102006754.html?noredirect=on
- https://www.pcmag.com/news/301010/years-late-and-millions-over-budget-fbis-sentinel-finally
- https://spectrum.ieee.org/riskfactor/computing/it/fbis-500-million-sentinel-case-management-system-still-has-major-operational-kinks-ig-reports
- https://www.entrepreneur.com/article/329019
- Textbook Ch 13, 14
A Response to Why Software Fails, and What Happens when it Does:
These articles offer devastating insights into how and why major projects fail. From the FBI’s ‘Virtual Case File’, which was an absolute garbage fire, to it’s still deeply flawed successor ‘Sentinel’, to a series of NASA projects which all failed due to similar organizational or programmatic mistakes, these articles tell a tale with one clear moral. Big projects cannot be entrusted to the ‘agile’ development process.
Well, perhaps that’s an overstatement. After all, there is a lot more to unpack here than simply blaming it on starting a project with no clear goals and no clear goalposts to track progress towards them. The NASA projects had, apparently, nobody testing or overseeing the code; they allowed the hardware developers to create their own software at times without properly testing that they would work well together in a complete whole, reused old code for new purposes without refactoring or even (apparently) considering if the code was suited or designed for such tasks, and allowed such things as a software failure state which shut down the machine when an unexpected input was received; an error which, predictably, caused core systems to shut down mid-flight and jeopardize the mission. If the NASA projects could be summarized under a blanket statement, it would be that the physicists and engineers had little to no respect for the software that would run their machines; and they paid the price with failure.
Meanwhile, in FBI-land, project management was the primary issue. When they started to design their new system, they didn’t start with a project structure, clearly defined requirements, and consultation from database experts. They put a resident tinkerer in charge and he was happy to figure it out as they went. Such a process is fine for a small script like he had been developing until now, but was utterly insufficient for the massive task of redesigning and reorganizing the digital paperwork of an entire global spy network. So, while they saved time by ‘starting immediately’, they ultimately lost half a decade and half a billion to create a system that was outdated the day it was released.
Another core failing of the VCF/Sentinel design process was how ongoing and micromanaged it proved to be. The FBI outsourced the programming, but instead of giving clear, concise requirements and letting the developers develop, they created (and constantly expanded upon) a near-800 page monolith of excessively specific designs. They engaged in a development cycle that involved so much micromanagement of insignificant details that the development process devolved into reactionary listening to orders. One can only assume that, under such conditions, any programmer would lose their spirit and simply do what the latest document says; independent of how poorly planned, redundant, unnecessary, or flat-out backwards the ‘new requirements’ would be. When the goalposts move so constantly, it becomes impossible to progress; one simply constantly plays catchup to ideas and decisions that when thought about too hard clearly aren’t leading anywhere, and especially aren’t leading to a project’s completion. And when you’re a contractor and you’re getting paid to do what they say, and when they wouldn’t listen anyways, why fight it?
The outcome to a lack of project management is not a bad product… it’s no product. These examples are extreme, but very real; software projects fail all the time due to issues like these. It doesn’t come down to having the best programmers, an unlimited budget, or even unlimited time. If you aren’t organized sufficiently for the scope of the project, you won’t succeed.
HW6: Chapter 4
4.5 Using the technique suggested here, where natural language descriptions are presented in a standard format, write plausible user requirements for the following functions:
- An unattended petrol (gas) pump system that includes a credit card reader. The customer swipes the card through the reader, then specifies the amount of fuel required. The fuel is delivered and the customer’s account debited.
The gas system shall be able to purchase a user-specified amount of fuel via credit card.
- The cash-dispensing function in a bank ATM.
The system must validate the user’s identity. The user must be able to withdraw money from their account; The system must physically output the amount withdrawn.
- In an Internet banking system, a facility that allows customers to transfer funds from one account held with the bank to another account with the same bank.
The user must be able to transfer funds from one account to another The system validates that the user has the right to withdraw from the target account The user must verify their target account before transfer The system should have a delay and verbose logging to allow for fraud prevention and recovery
4.6 Suggest how an engineer responsible for drawing up a system requirements specification might keep track of the relationships between functional and non-functional requirements.
They might make a hierarchical or strictly formatted document. The non-functionals which map cleanly to functionals could be on column 1, with their related functionals on column 2. Those with no clean mapping would be displayed in column 1 with no mirrored functionals (but these should be infrequent / nonexistent).
4.7 Using your knowledge of how an ATM is used, develop a set of use cases that could serve as a basis for understanding the requirements for an ATM system.
- Authentication of user with card & pin
- Viewing account details
- Withdrawals (up to daily withdraw cap or account total, whichever is smaller) (only in supported amounts) (only while ATM has requested amount in inventory)
- Deposit of cash (simple validation)
- Deposit of check (complex validation & delay)
- Transfer of funds between user-held accounts
- Receipts printed (option for email, none, as well)
- Secure log-out & auto-log-out-time-out
- Live recording system and tamper protection
- Secure Connection with Bank Network
HW7: Reflections
- https://en.wikipedia.org/wiki/The_Magical_Number_Seven,_Plus_or_Minus_Two
- http://cs.cofc.edu/~bowring/classes/csci%20362/docs/rfid-tire-pressure-2010-002-tpms.pdf
- https://www.markey.senate.gov/imo/media/doc/SPY%20Car%20legislation.pdf
- http://www.agiledata.org/essays/tdd.html
- Textbook Ch 4
Reflections on Test Driven Development:
Seven, +-2 covers some of the realities of human limitation. It’s core argument is that, given n stimuli, an average human will lose track after 7. This is the limitation of the human brain, and in my understanding seems roughly similar to the register-based storage within a CPU. Our working memory. Meanwhile, our memory span is the net capacity; the human brain can hold in each of these ‘slots’ a single concept. Note that since our brain works by reference and analogy, our internal ‘bits’ are concepts, emotions, or otherwise termed single elements. The most equivalent entry in a computer is described as a ‘bit’, but by my interpretation it seems more analogous to a ‘word’.
What this means for TDD? Well, if humans are so limited (and they most definitely are), then we will be significantly hampered when trying to debug or test code which does more than 7 things. In other words, any large project. In the zone or not, a developer is human, and simply cannot look at a large program project structure and see how everything impacts everything else, and where an error might be. Test driven development means that instead of trying to look back at old code and immediately become overwhelmed with ‘more than 7’ changes, we can instead write tests one-at-a-time while we still understand what the code does and is supposed to do. After all, we have limitations, but our tests are only limited by ourselves.
The Tire Monitoring System paper, meanwhile, shows that the State Mandated TPMS has a glaring security issue; it broadcasts the tire pressures within a vehicle wirelessly, and with a unique identifier; making any vehicle able to be tracked by simply scanning for signals and tracking where that unique ID is sensable from. While it is range-limited, this leads to the inevitable possibility of simply installing tracking sensors at common intersections; effectively tracing all movements of the vehicle (and thus, likely, the owner). The further tests and experiments show both that the system is significantly flawed and needs to be fixed; but some fixes can be recommended and solved with more development.
As a form of response, a bill was proposed to ensure cybersecurity requirements be enacted to protect the population from non-secure cars. These requirements include allowing users to disable trackable activities without loss of functionality.
What this has to do with test driven development?
Well, TDD is the process by which code is written, tested, modified, tested, modified, tested, etc etc. What it is most useful for is maintaining functionality after feature changes or refactoring; since the tests are already set-up, one can easily re-run them all and ensure that all old functions still work as intended. When new functionality is set up, new tests are also added to ensure that new functionality is performing as intended. The strengths of TDD is that code will be excellent at achieving the envisioned goals and issues, and will be reliable over versioning. However, the weakness of TDD is that it does nothing to ensure that any unexpected or forgotten flaws be detected and fixed; after all, if all the tests pass, the assumption is that the code works. If the test fails to account for a combination of events that end up being significant, then the developers will erroneously believe their code is perfect and possibly fail to address the issue in time. One might assume, therefore, that the Tire Monitoring System has fallen to such a pitfall; they envisioned the issues of a wired system, came up with a wireless one, tested that it could tell the car computer the tire pressures, and once it passed the tests, called it complete. However, since they forgot about security (or at the very least put very little time and effort into security), their tests were insufficient and a significant issue arose after deployment. However, I can hardly blame this on TDD - this is merely a guess. It is extremely frequent in nearly all development environments that security is overlooked, forgotten, or otherwise not prioritized. In addition, a testing environment is static and by definition predictable; compared the active chaos of having real humans pen-testing one’s systems.
Ultimately, Tests are the best way to determine that the code is functioning as intended. But one can still simply miss important elements of the design; a test you forget to make is a feature or contingency your software cannot be trusted to handle correctly.
HW8: Chapter 2
2.1. Suggest the most appropriate generic software process model that might be used as a basis for managing the development of the following systems. Explain your answer according to the type of system being developed:
- A system to control anti lock braking in a car
Waterfall.
You know exactly what it does, how it should work, and can easily predict the issues it might run into. IO is simple, the hardware is likely custom-designed by the guy in the desk next to yours, and your project has no room for errors. This is a clear cut waterfall software project. You can clearly define the scope, responsibilities, requirements, process, and timeline. Everything will go to plan. Similarly, due to the risk if it goes wrong, there is not a lot of room to be utilizing barely-understood code from ‘somewhere’. This must be done simply, and with a clear-cut process.
- A virtual reality system to support software maintenance
Integration and Configuration.
Virtual reality relies on many layers of softwares. The VR device itself will have a complex interface; but there are many existing engines and frameworks which make the process significantly simpler. While the ‘to support software maintenance’ part of this doesn’t make any sense to me as a VR project (do you want to visualize flowcharts in 3-d space?), the fact is that you’ll definitely want to utilize existing firmwares, hardwares, and softwares to simplify integrating the virtual world you are creating with this complex IO device. The functional part of your software has to be squeezed into a delicate framework of necessary integrated/configured elements. As such, this is the only development process option.
- A university accounting system that replaces an existing system
Integration and Configuration.
While, ultimately, every part of the software would probably need to be redesigned, it is also the case that there will be many existing tools (some internal, some external) which provide functionalities which are essential at a fraction of the cost (and fraction of costly mistakes) of self-developing these elements. Accounting systems could easily utilize an existing front-end while restructuring the database, or redesign the website while keeping the server the same. Meanwhile, login and account tracking features might be best integrated from utilizing a microsoft login framework, rather than reinventing the wheel of user identification and likely making some critical mistakes in the process. The database itself would likely be SQL-based - again, integrate and incorporate tried-and-true software elements to efficiently create an accounting system what is significantly cheaper, more modern, and quite likely more robust than attempting to start from scratch.
- An interactive travel planning system that helps users plan journeys with the lowest environmental impact
Incremental development.
This project sounds like it is complicated and hard to predict as to what variables must be considered, and how they are weighted. As such, incremental development is best suited. Start with the simplest core; a travel planning system that finds travel options and allows them to be selected. Add organization features. Add scheduling elements. Finally work on how those results are weighted and displayed. Redesign the weighting system with testing and feedback. Each stage is distinct as the software approaches completion; similarly, when the base is incomplete, the next step cannot be worked on properly. After all, you need to filter by ‘viable’ travel options before filtering those for ‘most environmental’. You can’t return before you leave even if that is the most environmental option. You can’t ‘leave’ from a neighboring country, and ‘return’ to antarctica. Basic features first; even if the core purpose of this app is environmentalism, you have to complete every step leading up to it before that ‘core’ can be developed.
HW9: Reflections
- http://cs.cofc.edu/~bowring/classes/csci%20362/docs/RapidDevelopmentChapter7.pdf
- https://hub.packtpub.com/11-predictions-for-the-future-of-programming/
- Textbook Ch 2
Reflections on the Future of Programming
With automatable testing and deployment, elements from the iterative design process will only become more prevalent. Meanwhile, with the significant majority of softwares having some form of access to the internet, updates and evolving scopes over time necessitates a software model which allows for future development and long-term support; but also for quick fixes whenever needed.
This suggests a future of an extensive and test-heavy auto-deployment process; The software will have evolving goals that each must be organized, designed, and completed. Miniature cycles of waterfall, to ensure that long-term-design parameters are fulfilled, but short duration and limited scope, so that features can be added as-ready rather than all-at-once. As a programmer, you work on a new feature or process for your particular sprint, then attempt to deploy it; the automated test/deploy system handles the rest, and you find out if you’re going to be bug fixing or moving on to the next thing.
This sort of process also necessitates a refactor process; this can either be a refactor cycle which repeats every n new-feature cycles, or a continuous process by a discrete team. At any rate, excessive attention must be made for software to follow interface rules, as this allows software portions to be rewritten or refactored without breaking the various dependents (especially those in unexpected areas). In a similar fashion, if one adds a new feature that calls an existing interface, and the existing interface has a bug, it is important to fix the old module rather than create code which relies on the module breaking ‘predictably’; doing so means that one’s own code is almost guaranteed to stop working the moment refactors get around to fixing the erroneous core.
Documentation and planning between sprints with this layout is absolutely essential; if only to keep track of which features have already been made. Modules being called in multiple conditions and situations is great for efficiency of code, but only if a developer doesn’t accidentally keep creating new ones with minor (or no) differences to existing ones. Well-designed and easily-parsed documentation combined with a modular design style for each module is essential, then, so that a developer can quickly discern what they need to write, and what they can utilized from the existing code-base.
This setup is very similar to the evolutionary-delivery model, but with some core distinctions. Utmost is the complete lack of a final version; software being ‘complete’ is by and large a thing of the past - and arguably was an unrealistic concept even then.
Meanwhile, the code should also utilize existing frameworks whenever possible. The more quickly and effectively the computer science community can settle on standards and unify frameworks, the better. We don’t need to be replicating work decades-old on an individual scale; we need to be using something that will grow with us. The greater level of integration of shared tools the programming community can reach, the more capable we will be (and our softwares will be) to evolve and continue to remain relevant as hardware, softwares, and protocols evolve; those frameworks themselves can integrate the best of the new, retain compatibility with the old; and softwares can make minimal changes in order to incorporate the consolidated improvements of constant development in places where the individual developer has neither the time nor resources to improve themselves.
Shared frameworks like Pandas, SQL, Docker, etc create a unified programming environment that constantly improves and allows code that imports/utilizes them to benefit in the shared progress. A greater emphasis on utilization of these tools in the future (and greater development of more/better tools) is an inevitability; and a very good one. While one must take care to utilize them correctly, software can only be improved by utilizing the best tools available; this approach is only going to become more true as computer utilization completely supplants traditional hard-copied styles of bureaucracy and documentation, and places greater focus on a small number of well-honed modular frameworks, rather than an infinite collection of distinct bespoke systems.
HW10: Chapter 5
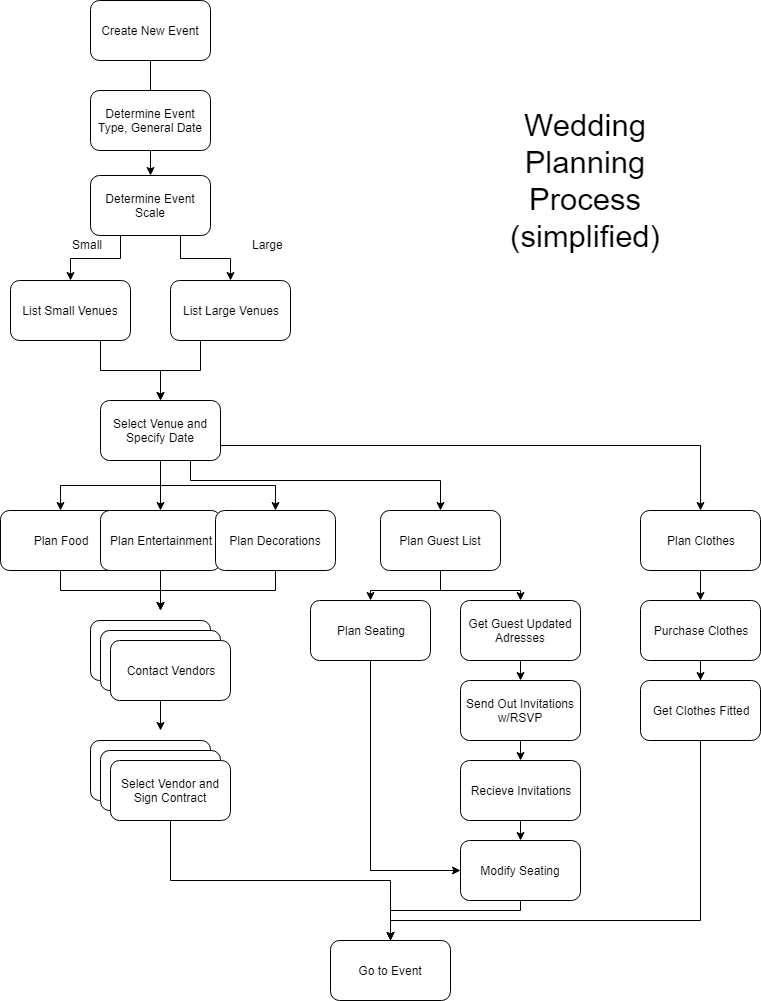
5.3. You have been asked to develop a system that will help with planning large-scale events and parties such as weddings, graduation celebrations, and birthday parties. Using an activity diagram, model the process context for such a system that shows the activities involved in planning a party (booking a venue, organizing invitations, etc.) and the system elements that might be used at each stage.
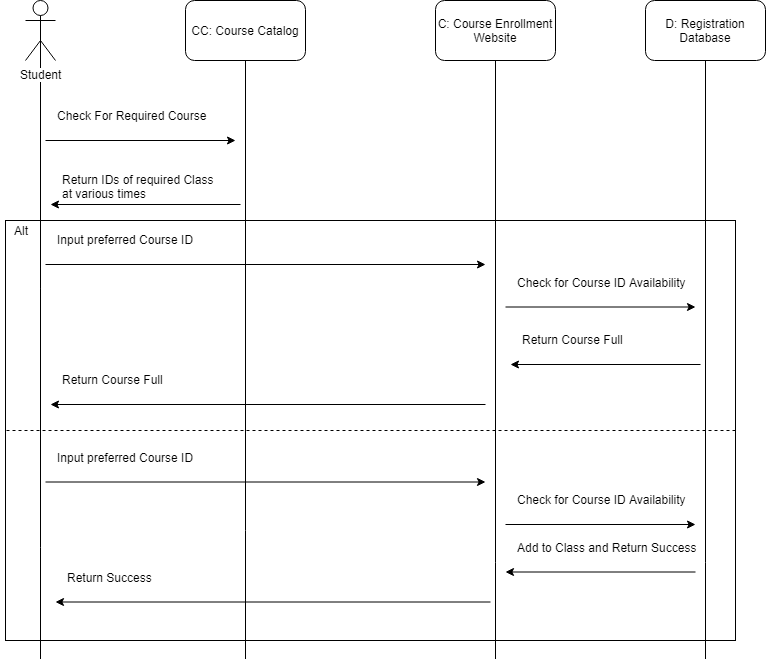
5.5. Develop a sequence diagram showing the interactions involved when a student registers for a course in a university. Courses may have limited enrollment, so the registration process must include checks that places are available. Assume that the student accesses an electronic course catalog to find out about available courses.
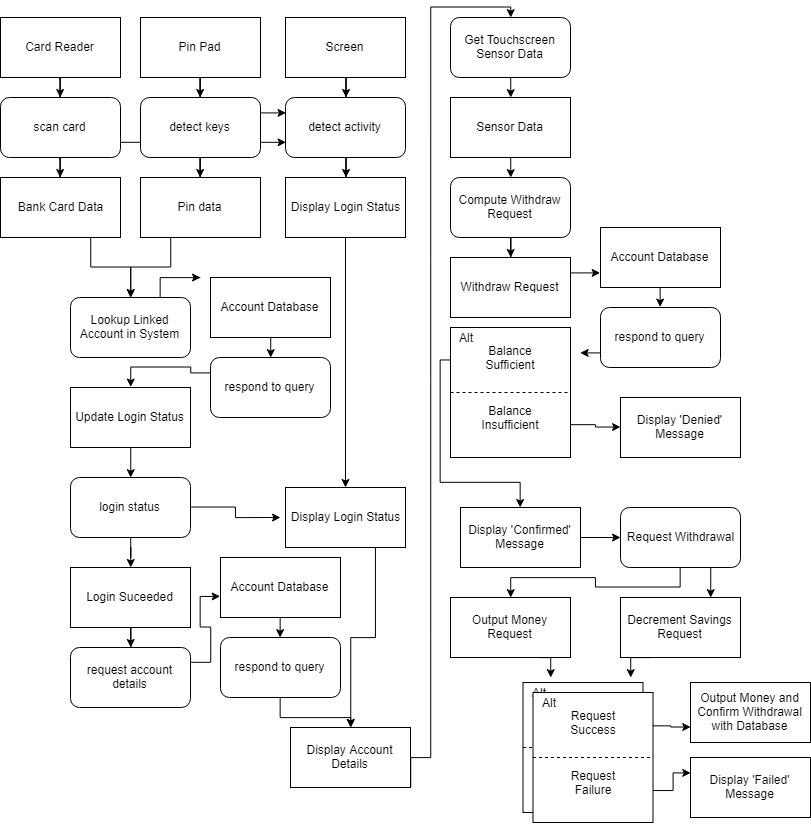
5.7. Based on your experience with a bank ATM, draw an activity diagram that models the data processing involved when a customer withdraws cash from the machine.
5.8. Draw a sequence diagram for the same system. Explain why you might want to develop both activity and sequence diagrams when modeling the behavior of a system.
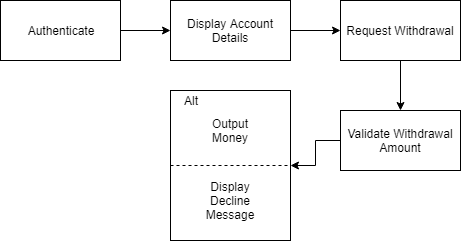
I would not want to develop diagrams because they’re extremely tiring and time consuming.
However, I would probably want to develop both activity and sequence diagrams because the activity diagram is useful for determining what has to happen in broad strokes, while the sequence diagram keeps it very clear as to what has to interface (and interpret) from what, in a more strict and descriptive manner. Both are useful for different reasons, and keep track of the software’s process at a different scale/level of precision allowing for a “bird’s eye” and “detailed” schematic which can guide development going forwards.
HW11: Chapter 6
6.4) Draw diagrams showing a conceptual view and a process view of the architecture of the following systems:
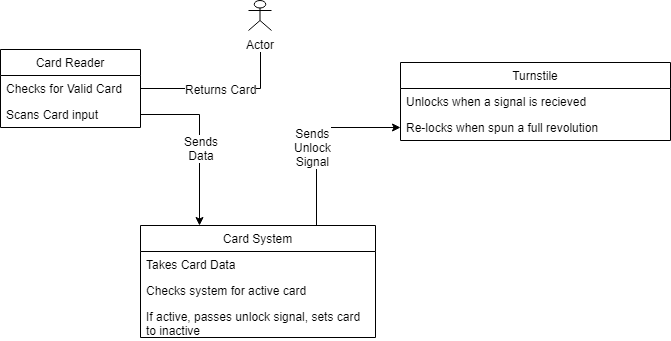
- A ticket machine used by passengers at a railway station.
Conceptual:
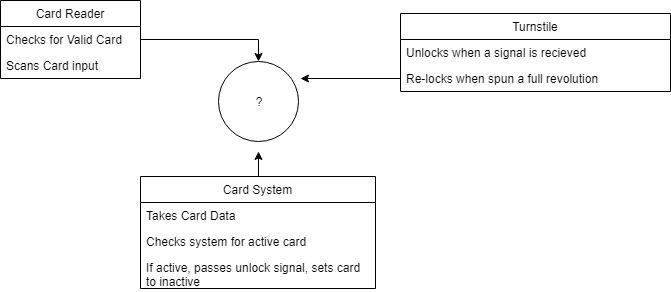
Process:
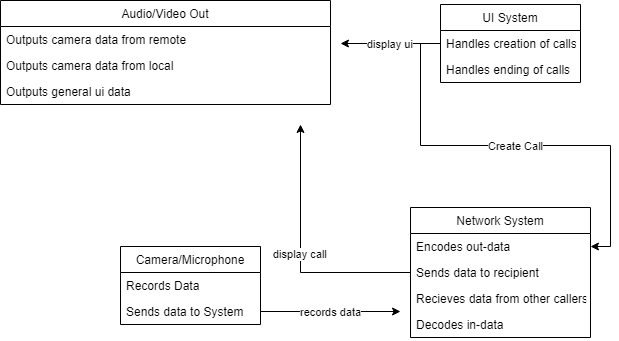
- A computer-controlled video conferencing system that allows video, audio, and computer data to be visible to several participants at the same time.
Conceptual:
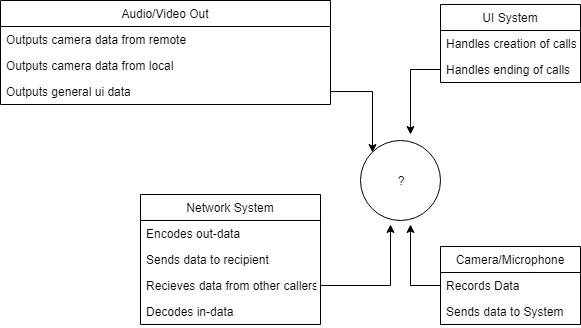
Process:
- A robot floor-cleaner that is intended to clean relatively clear spaces such as corridors. The cleaner must be able to sense walls and other obstructions.
Conceptual:
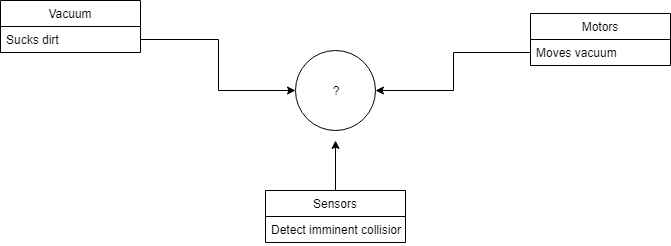
Process:
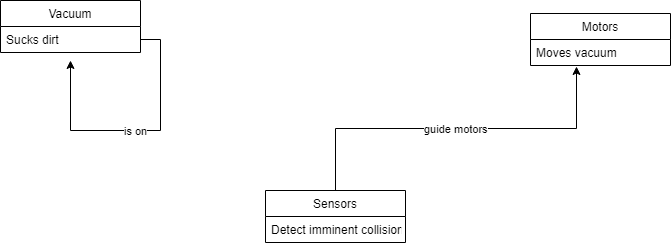
HW12: The Mythical Man-Month
- http://cs.cofc.edu/~bowring/classes/csis%20602/docs/The.Mythical.Man.Month.F.Brooks.pdf
- http://agilemanifesto.org/principles.html
- https://en.wikipedia.org/wiki/Agile_software_development
- https://www.cio.com/article/2385322/agile-development-why-agile-isn-t-working-bringing-common-sense-to-agile-principles.html
- Textbook Ch 3
Reflections on Mythical Man-Month; and Why Agile is Unsustainable
Mythical Man-Month, response and analysis
MMM starts off with an extremely astute observation as to the shared humanity, joys, and woes of programming. It is the magic of creation, but like magic, it is specific in it’s implementation lest you summon demons. It also finds itself frequently managed by others, and has layers of dependencies due to the fact that it is, in many ways, an apex field. What it speaks of, quite thoroughly at times, is the complexity and interconnectedness of the trade. But the title is about the “Man-Month”, and the myth thus contained. The Man-Month is an optimistic time estimate. “How much can we get done in a month, and can we make it faster by adding more people?” The Man-Month has an answer, but that answer is rarely correct; there is always more than was predicted, no matter what the prediction was. And when something is behind schedule, management wants to throw more people at the problem; people who cause chaos; people who make the process even more complicated, and even more behind schedule. For complex projects, an increase in manpower intended to aid will instead harm, and greatly.
What is also questioned is the process of scheduling; programmers are optimistic, but results are statistics. The author finds that, no matter what the intention or plan was, half of total project time is spend testing and debugging. So, rather than ‘falling behind schedule’, they build it into their plans. They also assign a higher stretch of time to planning (double that of the time spent coding), because a well-planned project involves less wasted effort, and thus ends up being more successful, faster, once it’s actually complete. Back to man-months, though, we now see the math behind a man-month-based disaster. For, when a project falls behind, and new individuals must be added; they cannot start immediately. They must be caught up, the project must be restructured, and all that time is still counting against the schedule. Only now it’s a higher number of wasted hours, because it’s compounded by the number of new people added. Moreover, this increase in manpower only leads to greater productivity when a project can be subdivided by the new number of individuals. If a project has two parts, then the third person is of little use. Their addition still adds complications, though, meaning that they are exclusively a drag on a project if not organized properly (which the addition of manpower mid-project would suggest is already the case).
In short, Brooks’s Law holds true: “Adding manpower to a late software project makes it later.” (pg 25)
Next, it questions team sizes; With the basic calculation (provided by the author and assumed to be true) that 1 good programmer is 10x faster than 1 mediocre one, it serves to reason that small teams of excellent programmers produce better projects faster; but the truth is, the numbers don’t quite add up. A team of multiple 1000s might be unwieldy and less individually productive, but the team of 10 (the maximum optimal team size according to the author), even being 10x faster individually can still not match the giant-scale operation in terms of timely production. So, Mills’s Proposal; the surgical team. Instead of 1 good small team, or a bunch of bad teams with good managers; why not turn it on it’s head; make a moderate number of teams with one good lead each, and mediocre support staff? Each staff member would contribute to the team’s productivity in a task-oriented manner, but in a way that enhances the productivity to the team lead, rather than detracting from it. What’s particularly interesting in the modern day, however, is that each of the staff member’s positions have been by-and-large made unnecessary. Many of the mechanics of programming, from automatic builds, to version control, to testing and logging environments which can be run a-la-carte; most of these positions no longer need to be handled by a human at a desk. The most significant position that still has meaning is that of the co-pilot; the sounding board who keeps track of the big picture and offers alternative ideas and looks behind the ‘team lead’. Some of these roles are quite fascinating, but are hard to place in a modern context. Therefore, since large structural changes in the mechanics of programming necessitate a redesign of this team structure, I have a hard time envisioning what a modern equivalent would be, and thus am unsure how much I agree with this proposed team layout.
Finally (for this blog post, at least), in chapter 4 MMM falls to supporting and reflecting upon its conclusions leading to this point. After all, we have seen the layout for a team of 10 where only one individual in that team is actually programming; the elite makes all of the decisions and is the only one to be trusted. This assumption; that there is a vast and fundamental difference between the peak and the pleb; runs counter to my personal culture and has concerning ramifications. Not just for if the assumption is true, but even more so ramifications if the assumption is believed to be true independent of reality. But, in fact, the author does not reflect on this issue for long; they merely use it as a bridge to talk about the virtues of conceptual integrity, or “how much magically better something is when it’s designed by only one person, or at least looks like it is”. Unfortunately, it makes a strong argument to support itself. The notion of a concise, simple project plan relies on few, experienced architects; thus making them the de-facto aristocracy. Highly difficult.
The agile Manifesto, line-by-line
The agile manifesto is a ridiculous and horrifying document; as such, I will insult it below:
Their “highest priority is to satisfy the customer through early and continuous delivery of valuable software”; this means that the user gets to feel in real time how long it takes to complete the project, as they’re sitting around using an incomplete project, and having plenty of time to get particular over details and start micromanaging.
They “welcome changing requirements, even late in development”. In other words, Agile loves to scrap a project and start over, which is lucky because they’ll probably do that a lot.
They “deliver working software frequently”; meaning that there is always a rush to deploy; which also implies not enough time to reflect or refactor.
They assert “business people and developers must work together daily”; this allows project parameters to change every day, which agile welcomes; developers, however, might find that they are unable to complete any goals because the goalposts keep being moved.
They “build projects around motivated individuals”, which is business slang for “overtime is required to make up for our poor planning and lack of time management”
They posit “the most efficient method of conveying information (…is…) face-to-face”, which means that anything that could be a single sentence email must instead be a scheduled meeting; again, good luck getting work done.
“Working software is the primary measure of progress”; which means that if you have to work on an important feature that is challenging, but on the backend; don’t bother. It won’t look like progress, and you have a build due soon in which the business people will want to see progress.
“Agile processes promote sustainable development” is an outright lie, as nothing about this process is anything but soul-crushingly unsustainable.
“Continuous attention to technical excellence and good design enhances agility” translates to ‘good programmers make better software’. Who could have guessed?
“Simplicity is essential” is a lovely mindset, but isn’t actionable. A non-functional requirement, one might say.
“The best architectures emerge from self-organizing teams.’’ Translation: your managers aren’t going to help with organization or guidance; they’re just here to make sure you give the business people whatever they ask for.
“At regular intervals, the team reflects on how to become more effective”. What better item to cap off agile than another pointless meeting?
HW13: Chapter 8
8.7. Write a scenario that could be used to help design tests for the wilderness weather station system
Gary is a guy who works at a remote wilderness weather station. He is currently stationed at a wilderness base. He wakes up, gets dressed, and makes breakfast. After drinking a nice cup of coffee, he sits at his desk, but does not log in to the computer; it stays powered on. The system is running already, constantly scanning for weather anomalies. But as there are no alerts visible on his screen, Gary knows that there is nothing that demands his immediate attention. Everything will be automatically logged and recorded, and he will be able to scan through a nice summary of the conditions and latest predictions if and when anything comes up to report on. He sits back in his chair and relaxes, trusting the weather system to warn him if anything happens, and thinking about Saturdays with the family.
8.10. A common approach to system testing is to test the system until the testing budget is exhausted and then deliver the system to customers. Discuss the ethics of this approach for systems that are delivered to external customers.
The implications of a limited-budget test system are generally negative. It’s an unethical (or at best ethically ignorant) system, due to it’s complete disregard for the quality of testing, instead reducing it to a simple number. It is also in ineffective way to structure testing because:
- Costs have nothing to do with quality: they can be high if resources are wasted, and low if they are used sparingly. A developer who wants to test thoroughly might stretch their resources thin and stay within the limit while wasting time. Contrastingly, a developer who hates testing might outsource it to an expensive consultant; he doesn’t care about the testing, doesn’t want to do it, and is happy to burn the money to get the testing ‘done’ more conveniently, but get a lot less testing for the money.
- Costs have nothing to do with time: Say the team decides to split one developer off to finish the testing while they move on to the next project. His budget might cover the ‘man-hours’ necessary, but with one man, those tests might take far too long. The project will end ‘on budget’ but not ‘on time’.
- Budgets can be incorrectly distributed: As many will admit, testing is few developer’s favorite part of a project. What, then, if the budget manager hates tests? ‘Here’s $5 for testing, make it work’. That will surely lead to a thoroughly and properly tested result. Definitely.
- Order of operations: ‘deliver when the testing budget is exhausted’ implies that testing is the final stage of the project. And yes, once the project is done additional tests will need to be completed. But testing does not start when the project ends; testing done properly starts before coding on the project begins; testability is designed into the core project structure, and is present in the process throughout.
- Artificial boundaries: Testing is not a disparate element that can be wholly separated from development’s other costs. Just as elements of testing are part of the planning process, and start before any programming beings, testing should also be a continuous process to validate and verify the project as it proceeds. A consequence of the 7 +- 2 quality of humanity is that we’re likely to lose track of details once things have piled up and become too large; this means making tests while one still understands the tested material. To achieve this, many tests will have to be done while coding, and will thus blend with core programming ‘budgeting’. And in so doing, the budgets for ‘testing’ and ‘everything else’ become inextricably intertwined and time sheets start getting really complicated. These budgets were never meant to be separated, and doing so causes more problems than it solves.
However, this system will continue to exist, despite these issues, because:
- A budgetary constraint has to exist.
- As much as we might wish otherwise, money and time are the two primary constricting factors in every project. Complaining about it doesn’t change that fact.
- Having a clear goal and clear limitations is helpful for everyone.
- Do we like the customers? Maybe this system is in place because the long-term requirements of the project are immaterial; it’s all about the sale. This very well might be the case if your business is run by business majors. It might be unethical, but they’re okay with that, and you work for them, not the client. Unless you work directly for a client; in which case, they set the budget. Either way, if the person with the paychecks is going to budget your testing, your testing is budgeted. So ethics are forced to bend to the realities of the business world.
HW14: Testing Reflections
- http://cs.cofc.edu/~bowring/classes/csci%20362/docs/software.testing.introduction.pdf
- http://cs.cofc.edu/~bowring/classes/csci%20362/docs/rep_and_analy.pdf
- http://cs.cofc.edu/~bowring/classes/csci%20362/docs/MutationTesting.pdf
If the files timeout when trying to open them, try this handy linux command:
wget --retry-connrefused --waitretry=1 --read-timeout=20 --timeout=15 -t 0 "http://cs.cofc.edu/~bowring/classes/csci%20362/docs/software.testing.introduction.pdf"
Reflect on the Readings about Testing
Software Testing Introduction starts with a very intimidating quote: “Testing consumes at least half of the labor expended to produce a working program”
However, while it goes in-depth into how disliked testing is, I think that such attitudes are primarily an artifact of time management, rather than one of testing itself being a miserable activity. After all, in an ideal world, your test environment provides more than nothing; it provides validation, and peace-of-mind. But coming back to that time management issue; when someone is simply ready for a project to ‘be done’, then anything that delays the deployment of code that is ‘mostly finished’ is the enemy. When testing finds no issues, it was a waste of time; when it finds issues, it’s a criticism of the quality of the work, as well as the enemy which creates more work. When viewed from such a perspective, who would ever want to test their code? And who might simply hope that their code is good enough to not need it?
But they do run into errors; many of which are found much more efficiently when tested correctly, rather than cropping up in the 11th hour. So it’s worth it to do it right.
One of the most fantastic of test-setups is, in my opinion, one where the tests are made first. After all, what is a clearer indication of progress than pressing a ‘test’ button and getting more green checks than the last time you ran it? What a magical experience coding could be if you knew, not only exactly what every function was going to be and do, but also that with barely a second expended you could know with reasonable certainty if that segment of the code was done; production ready; finally finished! Unfortunately, such a setup requires extensive planning and pre-documentation for such wonderful tests to be able to even exist; and even more time to create them all. Alas, if only every project could have already been designed by a world-class software engineer and we could just code without worry. But we’re the engineers here, and not every project has a client who is capable of making waterfall possible. So we’re forced to make do.
Phases of a Tester’s Mental Life (paraphrased):
- Phase 0: Utilize Testing to support debugging only
- Phase 1: Testing to prove code works
- Phase 2: Testing to prove code doesn’t work
- Phase 3: Testing to manage the percentage of working/not working
- Phase 4: Testing as a way of life; Coding to make testing of the code simpler and more effective, with testing itself as the end goal.
The phases in a tester’s mental life is an interesting segment; it mostly denotes a hierarchy of testing, where phase 0 is a programming grunt who has no understanding of what tests are nor should be, and phase 4 is one who has transcended mere tests and become a being of pure intellect. Clearly you want to be in phase 4… right? But these phases have a lot of details and curiosities even within them. Many of these phases have, for instance, evolved over real-world decades of industry experimentation; as such, they represent more than just the author’s opinion (probably). Meaningful insights such as this cutting remark against phase 1 - testing to show software works: “it is self corrupting. It only takes one failed test to show the software doesn’t work, but even an infinite number of tests won’t prove that it does” (p. 5). It goes further, by saying that even though the later phases may be more advanced, they’re all cumulative; they’re all valid.
Representation and Analysis also talks about testing, but from a different perspective; such as how to make better graphs of logic in order to make tests which account for every state and state changes; this uses the graph-theory layout of a program to better understand where tests need to be. This is very similar to a mathematical approach, as each state and state change can be attempted to be ‘proven’ once they’re clearly broken down in this manner.
Mutation in Testing, finally, looks into testing test algorithms themselves; how should it be done? They compared mutant code (code that has been semi-randomly altered to introduce errors), real faults (code with known errors), and hand-seeded faults (manually added errors) in order to determine which method, if any, is most effective and where the field should evolve when generating new testing frameworks. After all, feeding a framework the best possible data is necessary for getting the best possible framework (not so dissimilar to how a learning machine might require good data; and not necessarily avoiding using a learning machine, either). Their results were, unsurprisingly, that faults are hard to find in a generalist testing environment; most tests will need to be hand-seeded on an individual test basis to have much utility or validity. This has the implication that testing will likely not have a universal “test software” that can simply be bought and ran on any given code; tests must be hand-written on a per-project basis. The downside is that anyone who hates tests will likely never get away from them. The upside, though, is that testing is likely to continue to be a valid specialization. So that’s nice, I think.
HW15: Chapter 15
15.10. The reuse of software raises a number of copyright and intellectual property issues. If a customer pays a software contractor to develop a system, who has the right to reuse the developed code? Does the software contractor have the right to use that code as a basis for a generic component? What payment mechanisms might be used to reimburse providers of reusable components? Discuss these issues and other ethical issues associated with the reuse of software.
To answer the question: It’s in the contract. If it doesn’t specify, go wild. Probably. After looking up whatever the implicit licencings and laws are in the country you are currently living in.
But to look at the ethics of copyright, IP, and licensing, my approach can be summarized by “oh god oh god no why”. This is because the ethics are notoriously complicated, so much so that one might as well just figure out what the contract says and call that ethical, because it’s what matters anyways. Except that the contracts and licenses themselves can be quite complicated. Take, for example, the simple “CC BY-SA” licence; a permissive license that allows one to utilize the given code however you want, provided you acknowledge the source of the code and maintain the same license. But what license does your project require if you utilize code from two different sources with two different ‘permissive’ licenses who both require ‘share-alike’?
The truth is, in my honest opinion, code should not be covered under any form of copyright or copy protection. Whatsoever. This is because while code is “infinitely creative” in how it can be written, if you want it to actually work your code is going to look a lot like everyone else’s. And really, the entire purpose of programming is to find ways to make less work for ourselves, right? So why on earth is it that somehow we’re supposed to believe that copying good code is unethical? It’s the single most ethical thing you can do; maximize work done, minimize effort wasted. Utilize all that time and energy where you could have been busy reinventing the wheel, and instead use it to actually push the field forwards.
The fact that people are so bullheaded about claiming what’s “theirs” when in fact we’re all the same species with the same limitations, reading the same textbooks, programming on the same computers for the same language on the same operating systems (with minor variations, granted); but that somehow we expect to be treated as if our individual genius is such that “no one could ever write syntax quite like me”… not to be cruel, but humans aren’t that smart. And wasting so much effort to gain no progress just reeks of the worst of humanity’s tendencies to forget that ethics true greater purpose is to improve the world, not to drag others backwards.
If we let copyright protect code in the way that it was intended to protect literary works, the future of the field is an endless cycle of lawsuits. Even allowing code to be considered copyrightable sets a horrible and dangerous precedent. There are no ethics involved in supporting this distended pustule of legal skullduggery. The only ethical issue here is that we have allowed the current situation to happen.
HW16: Chapter 9
9.8: Briefly describe the three main types of software maintenance. Why is it sometimes difficult to distinguish between them?
-
Fault repairs to fix bugs and vulnerabilities.
-
Environmental adaptation to adapt the software to new platforms and environments.
-
Functionality addition to add new features and to support new requirements.
These seem like distinct processes, but frequently blend together simply by all describing the act of modifying old code. After all, if one is fixing a bug, they have to rewrite a small portion of the code; that portion might in the process become better adapted to new environments, or the developer might add a small new functionality while they are still in the region. When adding a function, new bugs may be introduced which must be fixed; and those bugs might arise due to a dependency which now must be better adapted to the new environment. Changing the environment of a large project might require vast rewrites; rewrites that might as well fix bugs or add features since those code segments are being altered anyways. In this way, from any one of the types of maintenance it is extremely easy to blend into another; or to put it another way, it is very difficult to not do a combination of them even if the original intent was only one.
9.10: Do software engineers have a professional responsibility to develop code that can be easily maintained even if their employer does not explicitly request it?
Of course they do. The entire purpose of software engineering is to make better code. Included in that definition is maintainability. Software engineers have a professional responsibility to create well-designed projects, which when done correctly makes the code easier to maintain.
HW17-A: Chapter 16
16.9. Design the interfaces of components that might be used in a system for an emergency control room. You should design interfaces for a call-logging component that records calls made, and a vehicle discovery component that, given a postcode (zip code) and an incident type, finds the nearest suitable vehicle to be dispatched to the incident.
Call-logging:

Vehicle Discovery:

HW17-B: Chapter 17
17.10. Your company wishes to move from using desktop applications to accessing the same functionality remotely as services. Identify three risks that might arise and suggest how these risks may be reduced.
1. Concurrency:
Many of the core functionalities of the application may be designed to be the exclusive user of a resource at any given time. For instance, opening a file which then stays open until the application is exited, which then overrides the saved file with the one in memory. This functionality, which is fine for the local app, would be ruinous for a networked software with shared resources, as one application may override the changes of another simply by having been opened first and closed last. This may be less significant of a risk if the application utilized network-friendly data storage methods, such as SQL.
To address this issue, care must be taken to ensure that there are no concurrency issues for all file/data-based operations. Moreover, data access cannot simply be rewritten to networked equivalents; in some cases the core logic of any given I/O operation may have to be revised.
2. Accessibility:
If the application has any large calculations which it performs, then these features must be implemented with great caution when put into a networked service. After all, if a client (or number of clients) connects to the service and ask it to run its most computationally intensive functionality, the service must be able to juggle its responsibilities such that no single client monopolizes the service; and that new users will be able to join and still have their user experiences unharmed.
To solve this, the application must be converted to utilize a task manager with hierarchies of tasks. This way, core communications can be given priority across all sessions and all users, while the expensive operations can be relegated to be given proportional distribution of the available remaining calculation space. Another option might be to make for ‘fat’ clients; where these heavy calculations are given to the client rather than the server; but this solution might not be available depending on the specifications of the project, and comes with its own issues.
3. Security:
The most significant feature which a local application does not have to account for is security; after all, if you’re logged into the computer and able to open the app, you’re probably supposed to be there. However, networked services have no such protection; anyone in the network (which could likely be the global web) may interface with the service. This means that security becomes a significant issue; by having every application user’s information stored and computed within this networked service, it creates a significant potential for a malicious entity to intercept, view, or alter this data; with potentially ruinous effects on the individuals under attack. Therefore, remote services must have significant and extensive security in place, to protect the confidentiality and integrity of its processes.
The only way to solve security is to take it seriously. Most likely, all aspects of validation, verification, and communication between client and server will have to be redesigned in order to take advantage of modern network security frameworks; luckily, many of these frameworks are becoming increasingly well-designed and easy to implement, making security approachable as a requirement, despite never being truly solvable.
HW18: Chapter 18
18.4. Define an interface specification for the Currency Converter and Check credit rating services shown in Figure 18.7
Currency Converter:
- utility service
- task-oriented
- not independent; relies on access to current exchange rates
- state not stored
Interface:
<interface name = “currency-converter” >
<operation name = “get-conversion” pattern = “wsdlns: in-out”>
<input messageLabel = “In” element = “c-conv:from-amt” />
<input messageLabel = “In” element = “c-conv:from-curr” />
<input messageLabel = “In” element = “c-conv:to-curr” />
<output messageLabel = “Out” element = “c-conv:to-amt” />
<outfault messageLabel = “Out” element = “c-conv:InDataFault” />
</operation>
</interface>
REST:
- no security required, ease of access primary importance
- Example url-based REST implementation:
- baseurl/ ? amount= VALUE & from= CURRENCY & to= CURRENCY
- e.g. <www.example.com/currency-converter/?amount=123-45&from=USD&to=JPY> to convert 123.45 US Dollars to Japanese Yen
Credit Rating:
- more secure, authentication required(?)
- business service
- task-oriented
- not independent; relies on access to credit monitoring systems
- state not stored
Interface:
<interface name = “credit-retriever” >
<operation name = “get-credit” pattern = “wsdlns: in-out”>
<input messageLabel = “In” element = “cred-ret:user-ID” />
<input messageLabel = “In” element = “cred-ret:password” />
<input messageLabel = “In” element = “cred-ret:target-ssn” />
<output messageLabel = “Out” element = “cred-ret:cred-score” />
<outfault messageLabel = “Out” element = “cred-ret:InDataFault” />
</operation>
</interface>
SOAP:
- Should require authentication & more advanced user logging
- Shouldn’t be URL-based due to the inherent security required regarding usage of SSNs
- Must track users & permissions within the system
HW19: Chapter 19
19.3. Why is it impossible to infer the emergent properties of a complex system from the properties of the system components?
An emergent property is any property that a system has which its components do not. In a component-based software, the core intended property is itself emergent. But other properties, such as unintended functionalities or very unintended failure states, can also be deemed emergent if they are a result of the combination of components. Because of how broad this definition is, therefore, there are many kinds of emergent properties, most of which share only one trait; unpredictability.
The issue with the emergent properties of a system is that they are often fundamentally different than the properties of any of that system’s components. The textbook uses a perfect example; the properties of a bike (transportation) are fundamentally different than those of its parts (gears, chains, wheels). An emergent property can be in many categories, and affected by many factors. For instance, there is no bug-free hardware, software, or user. As such, when looking at complex systems, we are frequently not looking at a single instance of error in one location, but a chain; perhaps this error state in component 1 causes an error state in component 2? Perhaps it doesn’t, but instead reaches an unusual state that was not supposed to be accessible. Thus, unexpected emergent states occur, not all of which result in complete software failure.
The first limitation of inference, therefore, is that any individual component only supplies a tool to be utilized by the system; one which can be used in any number of unpredictable ways. Take pandas, a data-science component which allows for complex table-based operations and calculations. Alone, all it really does is allow the software to organize and generate data; but how that data is received, stored, interpreted; these pandas doesn’t know or care about. This could be part of a software which analyses census data to make voting predictions, or part of a security software which does table-based calculations to compare data extrapolated from a photograph of an individual against that of the ‘key’ user. All of these uses are emergent; the functionality of the part enables the functionality of the whole, but is otherwise almost entirely unrelated. Because of this, simply knowing that a software utilizes Pandas gives very little actual insight into what the software actually does; its emergent properties are impossible to guess.
Another implication of this is a topic which the sci-fi community loves; the emergence of true A.I.; the singularity. What happens when you combine a learning machine with time, self-evolution, and unlimited computational resources? Presumably, something which is more than the sum of its parts; something that could not have been deliberately designed, but which might create itself if placed in the correct environment. Here, the potential emergent property is intelligence… but when/where/if/how it happens is nonetheless uncertain. In a less lofty example, a database is not intelligent, nor are a series of if-statements; but combine them in the right way, and they could pass the Turing test. The emergent property now is the illusion of intelligence… or is it the real thing? Is our emergent property more than we intended, or less?
Another inference issue is that large component combinations can lead to another category of unintended emergent properties; unusual and unpredictable bugs. A system comprised of other complex systems has an exponentially greater complexity than that of the individuals; this is basic combinatorics. In software, many ‘components’ are themselves softwares. The possible combinations of subsystem ‘A’ states alongside subsystem ‘B’ states all the way through the possible states of subsystem ‘N’; these combinations become computationally intensive to even estimate, let alone try to make a single software explicitly account for every one of them. A component software will instead seek to limit the states to well-understood ones that serve the purpose of the system; and otherwise, mostly hope that things don’t go in an unpredictable direction. The combination of failure propagation and the potentiality for non-deterministic results from a black-box component means that any failure could have any outcome; but likely further failures. These failures can be mitigated, but not entirely prevented. Such a system could accurately be described as “putting bees in a box and waiting for honey”, as you can’t control any individual element, but if you set up the environment correctly you will still likely get the intended result.
This uncertainty is further exacerbated by the black-box mentality. On the one hand, trying to understand every component is a complete waste of time and energy. On the other, not knowing how a component works (and doesn’t) might lead to finding a flaw at the worst possible time; possibly after deployment, when one of the aforementioned unexpected state combinations occur. At the same time, as a software grow in complexity, so too do components; any individual component utilized by your software might itself be made up of many more other components which you know nothing about. The potential depth of this recursion has no limit. This, combined with 7+-2, means that trying to understand every component, state, combination, and sub-component is a fool’s errand. Ultimately, the best you can do is test the things that you intend to use so that you have a hope of understanding some of the most predictable unusual states, and hope that the ones you have missed don’t occur; or at least don’t occur too often.
HW20: Chapter 20
20.10. You work for a software company that has developed a system that provides information about consumers and that is used within an SoS by a number of other retail businesses. They pay you for the services used. Discuss the ethics of changing the system interfaces without notice to coerce users into paying higher charges. Consider this question from the point of view of the company’s employees, customers, and shareholders.
This question is worded confusingly, so my translation is thus:
- Employees == The people working on the service and developing it.
- Customers -> Clients == The companies which are utilizing the service and paying to do so.
- none -> Customers == The people who are being tracked by this system.
- Shareholders == The people who have a financial interest in the success of the company making this decision.
Employees:
Anyone who knowingly works on an unethical project is themselves unethical. Anyone with a computer science degree doesn’t have an excuse for not knowing. Ethics aside, though, employees will have to ensure they don’t go down for this when it all goes wrong. They have two options; get written proof that what they’re being asked to do is exactly as they believe, and/or quit. The proof is a good idea either way, because if this goes poorly for the company, they’ll be looking for someone to blame.
Clients:
Coercion isn’t ethical. This is how you lose clients, who might decide that instead of paying you more and having to redo the work re-implementing your service, they’d rather not. They might even replace your system with that of a competitor; after all, they have to redesign their interfaces either way. This gets even more complicated if you are part of an organizational or federated SoS; the other companies who provide the other services (which collectively form the SoS that the client utilizes) may have rights, and your company might have responsibilities to those other member providers that are not being respected with this action. If your company is unilaterally acting against the interests of the Organization in an organizational SoS, then I would expect backlash; not just the replacement in the SoS of your service with that of another company, but the possibility of the organization blacklisting your company from other projects as well.
Customers:
Tracking and redistributing customers’ personal data isn’t ethical. By being so blatant with your fleecing of this data, you are making enemies who might bring to the attention of the court system that you are profiting off data which isn’t strictly speaking yours. Laws regarding the rights of an individual over their own personal data have lagged behind technology; you might make history in helping those laws catch up.
Shareholders:
Shareholders in this business are investing in an openly unethical business. They should either influence the company to make better choices, or move their investments elsewhere. While this action may appear immediately profitable, the short term gains for the company will be outweighed by the long-term effect of bad business and acting in bad faith. Investors might not care about ethics, but they will care when bad ethics lead to loss of clients, or worse, lawsuits. That said, this direction might have come from the shareholders, as they are frequently the least scrupulous and most profit-focused. They might even intend to scupper the ship deliberately if it aligns with their other interests, or if they want to sell their shares during the initial bubble for maximum personal profits. Such activities might be unethical and despicable, but they’re predictable nonetheless.
HW21: Team Progress I
Deliverable 3: Reflections on a Term Project Halfway Done
Mirror of: https://github.com/csci-362-02-2019/2-2/wiki/Deliverable-3:-Chapter-3
Architecture
Our testing framework focuses on a cyclical process of running tests on each test case one at a time, adding each to the output file. As such, the parent script, scripts/runAllTests.py does most of the heavy lifting. After resetting and opening the output report file, it loops through each file in the testCases/ directory; passing each file to scripts/minigen.py to be generated into an executable testable file within testCasesExecutables/.
Next, runAllTests sends a command via subprocess, asking the operating system to npm start with a pipe to catch the output. npm has been configured to interpret the command npm start as node testCasesExecutables/test.js; this is how the standalone generated test file is executed, as javascript requires a virtual environment such as a web browser, or Node.js, in order to be executable; javascript alone is not runnable without such an environment.
The console outputs are caught by the subprocess pipe, and sent onwards to oracles/oracle.py alongside the test-case-determined target value. The oracle determines if the test has been passed or failed, and returns that judgement back to runAllTests, where the results are formatted and appended to the growing report. Once this loop has been completed for all test case files, the execution and logging are complete; the report file reports/testReport.html is opened automatically, and the process is finished.
How to Run
Prerequisites:
As this project is javascript-based, there is one significant prerequisite installation before any tests can be executed; Node.js. Node, alongside its in-built package execution manager npm, makes up an environment in which javascript can be executed. This is dissimilar to most languages, where they have a central compiler and executor that is core to the language; in javascript, the code is merely written standalone, trusting that a web-browser or environment will come along and execute it automatically when the (likely html) file embedding it is loaded. Our other prerequisite is the ubiquitous Python 3. Given that this framework is intended to be run on Linux, therefore, the only concern is in downloading and installing Node, which can be done with the simple commands sudo apt install nodejs followed by a sudo apt update, and possibly additionally a system restart. We have managed with continuous development to remove any possible npm i or pip installs as requirements - so after this you should be good to go.
1: Initialization
Your first step is to ensure that any files which you want to test are present in the project/src/ directory. These files must be .js, and additionally, they must export a unit-testable function in order to be testable in this framework.
Second, you must ensure that your test cases in ‘testCases/’ are written correctly. The testcaseTemplate is as such:
TestID:%
Requirement:%
Component(filename):%
Method(functionName):%
Input:%
Output:%
Where the % must be substituted with the related details.
2: Running the Tests
Assuming the test file is valid and the test cases are done correctly, all you have left to do is run the script!
First, ensure your terminal is located at the head of the TestAutomation/ directory. If not, none of the scripts will path correctly; this location is specified in the project documentation, and is a hard requirement. Once you have successfully cd TestAutomation, simply type in Python3 scripts/runAllTests.py. After a minute or so, your report from running all of the tests specified will automatically open!
Modifications and Improvements
Deliverable 3 saw the rethinking and redesign of many core components of our testing system, mostly categorized by a removal of usage of existing frameworks, and a restructuring to support the use of our own code in their place. We went from simple .sh scripts which called the configured frameworks to execute themselves, to a more verbose python script to fully control all steps in the new, much more manual, main software execution sequence. Each broad segment of our redesign is detailed below.
Removal of Mocha Framework and Creation of Own Oracle
The Mocha Framework, as an extension to the core testing functionality of Node.js, was originally utilized for its ease of use and quality of testing design. With it, we gained access to the ability to have a function call wrapped around a .expects in order to automatically utilize a built-in oracle with attractive formatting of results. This, when further combined with the initial use of the mochawesome mocha extension, allowed for an npm test command to execute all test cases, compare their results, and generate it all into a well-formatted html file. However, while the purpose of this project is to ostensibly utilize all the tools at our disposal in order to get the best results possible, this extensive utilization of frameworks was deemed by our team to be taking this concept too far; better to write our own code for this one, to prove that we can, and save the frameworks for future testing of real-world software projects.
Therefore, we configured a variant of npm start which simply executes an extant singular test file, and wrote our own oracle which is piped the console outputs of the test file’s execution alongside a value representing the expected output, returning a pass/fail. While this process may be rudimentary when compared to the combined powers of mocha & npm test, we feel they better represent the spirit of the assignment in terms of writing our own code and functionalities from scratch.
A surprising advantage of this change, however, is significantly greater control of text execution outputs and piping. While mocha initially seemed a perfect framework, and mochawesome an attractively formatted report, they were nonetheless significantly limited in their customizability. So while they prove to be a simple ‘catch-all’ solution to testing for generic javascript code, they produced many outputs, such as automatic error handling, which got in the way of our own custom report requirements. Thus, formatted report generation is simpler with a handmade oracle, if only because our oracle outputs can now be designed specifically to work well with the specific report style that is intended for this project.
Test-executable Generation Based on Interpretation of Test Case Files
Another major rework of our project since Deliverable 2 is the understanding, and correction of, our test case pipeline. Initially, our assumption had been that the verbose test-case syntax of mocha meant that our test cases and our test case executables could be the same file; in fact, in a real world testing situation, this would be the case. However, we had missed the fine print; in this project, our test case files must be simple txts, not pseudocode, and not real code. Thus, our readable test case files would have to be read, interpreted, and generated into executable code on a per-test basis. This change was not difficult, but represented a shift in our approach to our project; instead of achieving the goals of the project in the most effective and efficient way possible, we were now reading the details of a very explicitly specified software project. This may have been an intended lesson; getting the correct result is immaterial if the methodology does not match the project specifications.
Removal of Mochawesome Framework and Piping of Executable-Run Outputs to Custom Report Generation
A further redesign came in the shape of fixing the layout of our reports generated from our test executions. When coming from an auto-generated report, moving to a self-made file left us with an initially raw output; the report went from something colorful and interactive, to a sequence of blocks of console output with no formatting and little design; this was largely due to the fact that our development cycle went as far as a minimum viable product as a report then focused on larger issues elsewhere. As we came back to report generation, therefore, design requirements had changed and our report would as well. While the new report is a significant improvement from our older working model, it still has many planned improvements before it can become framework-quality.
HW22: Chapter 21
21.4. Explain why an object-oriented approach to software development may not be suitable for real-time systems
Objects require instantiation, eat up memory while they’re sitting there (potentially not being used), and because they are self-contained, may internally contain duplicate code or features. All of these traits lead to bloat; bloat interferes with speed/efficiency, and speed is essential to a real-time application.
-
With a constantly-running real-time system, an object that is instantiated and not used wastes memory & energy maintaining its state. This degrades efficiency & speed; wastes energy, and could lead to failure by failing to react quickly enough.
-
Objects also are very strict in their interaction rules; this might lead to an overly limited framework which limits the theoretical reactivity of your system. Moreover, if you want concurrency with objects, you would need to instantiate multiple duplicate objects; this is a massive waste of resources.
-
Objects fill real memory space, placing additional restrictions on the hardware range capable of acceptably running this system.
-
Objects represent an additional layer of abstraction. While this may make code easier to write & understand, it also means a potentially time-costly additional step in communication between the input, calculation, and output. Moreover, objects often follow the black-box approach; hiding internal attributes which delays the system accessing those values.
-
Finally, The more functionality placed into an object, the more features fail if the object fail. Objects might reduce the robustness of a real-time system for this very reason.
For all these reasons, object-oriented is not a good real-time approach
HW23: Chapter 22
22.6. Fixed-price contracts, where the contractor bids a fixed price to complete a system development, may be used to move project risk from client to contractor. If anything goes wrong, the contractor has to pay. Suggest how the use of such contracts may increase the likelihood that product risks will arise.
The major issue with any contractor bid job is that it literally goes to the lowest bidder. The software will have to be developed on a shoestring budget, with the absolute minimum in terms of resources. Moreover, the relationship with the client is almost inherently contentious; they want to pay the least for what they can get, which will color all interactions because they will naturally feel like maybe they could have paid even less - whereas you, the contractor, will feel like you’re being wrung dry.
By making a contract fixed-price, it creates additional pressures. The exact final cost of the project has to be estimated perfectly. Since any failures, mistakes, or complications have to be eaten as expenses to the contractor, the base price of the bid has to be high enough to account for this risk factor. But by placing so much weight on an accurate estimate, there is a human instinct to round down on the costs, especially when trying to win that contract. So mistakes won’t be in the budget. This method might work when a unicorn project has no issues, and it might be okay if your planning (and estimates) are exactly perfect. And, for startups who don’t care about the quality of life of their developers, and who are happy to make 80 hour unpaid workweeks to get the project done, fixed-price might seem like a magic ‘I win the contract’ button. But in the all too common case where initial estimates are optimistic to the point of unrealistic, a fixed price contract could literally put a contracting company out of business.
All of this translates to extreme pressure on developers if (and when) they run into challenges. There is a significant likelihood that, when a challenge occurs that doesn’t fit within the strict budget and tight schedule, it will not be handled properly, but will instead be ‘mitigated’ and moved on from. Which translates to a software, in the end, which is held together with scotch tape.
Ultimately, this practice, like many others, is an outcome of business people making decisions from a purely capitalistic point of view, ignoring the human cost. And it’s successful, because people will almost universally let themselves be exploited. In the words of Joan Robinson, “The only thing worse than being exploited by capitalism is not being exploited by capitalism”. We’re the resource that’s being exploited. These contracts are just the mechanism by which the environment to do so is fostered and fomented.
HW24: Chapter 23
23.6. Figure 23.14 shows the task durations for software project activities. Assume that a serious, unanticipated setback occurs, and instead of taking 10 days, task T5 takes 40 days. Draw up new bar charts showing how the project might be reorganized.
Assuming that the project is being done by one team approaching tasks in a linear fashion, there is no reorganization to be done. While T5 takes longer than expected, the project won’t be getting completed any faster by moving things around. As we learned from The Mythical Man-Month, making changes to the team composition mid-project rarely has a positive effect. As such, it’s really better to accept the 30 time units lost than risk losing more by changing the project setup further.
That said, if the team was already split into two development groups, or could easily have it done so, then the distribution could look like this:
Due to the dependencies allowing some leeway in terms of splitting into teams and parallelizing the work, this two-team model almost perfectly breaks the requirements into semi-independent groups. Note, however, the semi. This is for two reasons. First, because at the very end, T15 and T16 are quite linear, so at that time I merge the two groups to finish the project off. Secondly, and far more significantly, the teams are not completely independent because both teams work on things that the other team will eventually require. For instance, when Team 2 gets to T9, T6 will have to have been completed by Team 1 already. Scheduling-wise, Team 1 should have completed T6 a full 20 time units before Team 2 needs it, but if more delays occur in this project, the multi-team schedule will prove increasingly complicated to manage.
The advantage of parallelizing as much as possible, though, is potentially faster overall project completion. In the graphs for the two-team split, I doubled the time estimates for all tasks for each team, as they are working with half the manpower. However, in reality this number could be significantly lower (or significantly higher) depending on the composition of each team and the tasks that they are suited for. For instance, if there are fifty developers on this project, then splitting the teams would absolutely be a good decision; I would want to split them into even more groups wherever possible. But, if we have only a couple of developers with significantly different skill sets, and all of the tasks rely on a mix of all the various skill sets, then I would redesign the tasks to better diversify the skills required, and still split the teams. But if they work really well together and really poorly apart, or if you have only one programmer, then obviously the linear approach would have to do.
The core factor comes down to understanding your people, and organizing the project in the way that best utilizes their skills and creates the least friction. Of course, that’s much easier said than done, but the theory is sound.
HW25: Team Progress II
Deliverable 4: Reflections on a Term Project Mostly Done
Mirror of: https://github.com/csci-362-02-2019/2-2/wiki/Deliverable-4:-Chapter-4
Improvement through re-implementation
Deliverable 4 saw our unit testing framework tested against, and re-designed to work with, object-based components. We found this necessary because our project has a severe shortage of pure functions; nearly everything in the nightscout repository is, in fact, an object. Unit testing of functions is great and simple; you import the file, pass the function name, pass the value, and it returns an output that can either agree or disagree with your expectations. Object-based unit tests, however, require a few more steps to the process.
The testing scenario for an object goes as such:
- Initialization: creating an object and giving it an initial state such that an internal function can be tested
- Testing: calling the unit-test target function on the object
- Post-processing: in the case of a function that returns an object, running the ‘getter’ necessary to actually receive the value produced in step 2.
Compare and contrast to the function testing scenario:
- The whole thing: calling the function, which returns a value
Our original test-case pipeline was not well suited to the new process, as it only supported the one step; the ‘middle’ part of an O.O. test. Thus, redesigns were required.
Redesign 1
Our first variant involved no changes to the test cases or executable generator at all; it was merely hacking together a functioning test. In our test-case layout, we kept it as
filename:
function name:
input:
output:
but made allowances by adding a new parameter: *args:
thus, any non-function object calls could be placed like so:
function name:function
input:inval
*args:.get()
which would translate to, roughly: function(inval).get()
however, the *args were not an elegant solution when we realized some objects had to be initialized in particular ways. For instance, how would we parse functionName.input vs functionName(input)? Clearly another design was required.
Redesign 2
This one didn’t last very long, but it’s here anyways. Part of the evolutionary design process is having dead branches to the family tree, after all. We considered that, perhaps, the issue was the type of test being run. For instance, if you’re testing a function, it needs the (), and if you aren’t, it doesn’t. Simple, right? With that in mind, our next design was implemented.
Method being tested:
Input:
Isobject:
The idea was that functionName(input) could have an isobject of 0, and functionName.input could have an isobject of 1.
But what about functionName().input, the function that returns an object? Or even function1(input1).function2(input2), the function that returns an object of functions? A more dynamic approach was required, and as such this design never got past the theoretical stage.
Redesign 3
The final and current design, therefore, had to account for dynamic number of objects, parameters, and functions, in any order. After all, why would we go through all the effort of making the test cases accept function().objcall and not accept objcall.function()? We had to go full optional number of parameters. As such, we went with a fully * optional call line, and a fully * optional param line. The new implementation is like so:
component:
(opt*)call:
(opt*)param:
and can be combined in any permutation necessary. For instance, what if the file import is itself a constant?
component:constant.js (no lines following)
-> which generates into component when called
What if the import returns an object, the function is behind a subobject and takes no parameters, and the answer is only accessible by getting the 1st index of a method called on that object?
component:crazyobjects.js
call:objmethd
call:function
param:
call:resultmethd[1]
-> crazyobjects.objmethod.function().resultmethd[1]
While this loses some elegance, one must admit that testing this particular case has very little by way of “elegant” solutions. And these are exactly the kind of objects we’re dealing with. Take languages.js, for example. To get it to translate a word, our test case looks like this:
Component:language.js
param:
call:set
param:'fr'
call:translate
param:'Clock'
which generates into this:
language().set('fr').translate('Clock')
We hope that y’all agree when we say that, though we admit the redesign lacks the simplicity of a pure-function testing environment, it gains far more in functionality than it loses in elegance. Either way, it was necessary.
HW26: Chapter 24
24.6. Explain why program inspections are an effective technique for discovering errors in a program. What types of errors are unlikely to be discovered through inspections?
Program inspections are the process of peer-review without testing. This is often line-by-line, and as such, has strengths and weaknesses when compared to a test-driven review process. The strength of this process is that reviewers themselves are programmers; thus, if they see a piece of code, and remember writing something similar (or different) to achieve the same functionality, then somebody will improve; either the reviewer sees something in the target code that they will learn and bring forward to their own projects, or they will see something that they deem problematic design because of their familiarity with that element of design, and will be able to suggest an improvement. Either way, the project wins. This is further strengthened by the fact that the original developer knows their code will be reviewed, so they will be incentivised to make their code readable wherever possible. This, again, ensure everyone wins.
However, there are many error types that do not synergize well with this technique. If code does not adhere to the style preferred by the reviewer, then they may have a difficult time parsing the code in their minds, and will likely complain about style but be unable to catch any errors beyond that; worse, their complaints about the style might force the original developer to redesign their code in a style they themselves are less familiar with, creating another realm of potential errors that must be caught and reviewed at a later date. Other errors which would be hard to catch would be ones which are simply hard to understand at all. If a target algorithm is sufficiently complicated, no amount of staring at it will allow a code reviewer to glean any meaningful insight into how (or if) it works correctly. These complex cases are far better suited to test-based scenarios, where one might statistically ‘prove’ the algorithm’s correctness, rather than simply stare at it and try to puzzle it out.
Due to the variety of methods in any large software, there is a guarantee that some will be better understood and improved by looking at them and imagining how they might go wrong; whereas others must simply be run to determine where they do go wrong. A balance of both approaches, therefore, is required for a truly robust quality management and review process.
HW27: Chapter 25
25.10. Describe five factors that engineers should take into account during the process of building a release of a large software system.
-
Version Control Consistency When everyone is working on different portions of an update, or worse, different updates entirely (re; one team bug fixing version 1, another team mostly done with version 2, a third working on starting version 3), the variants on the code base reaches ridiculous levels. Ensuring that all of the things that belong in a release are present, while not accidentally including some code that is not intended for this particular release, requires a significant effort.
-
Required Files Ensuring that all things, such as data files, config files, and updater are all in proper locations, versions, and updated for this particular release. A lot of these semi-documentation files get edited a lot, so care must be taken to ensure that they final build does not accidentally ship with debug mode enabled, for example.
-
Timing Software systems don’t exist in a vacuum, and a single release of an evolving software is a mile marker on the path of this software. Thus, timing is a significant factor in a few ways. Firstly is market-based timing; otherwise describable as ‘how close to release is my competitor?’ This provides an influence on the timeframe for this release, and how aggressive it must be. If a competitor is releasing a major update to their software, then your team might want to do likewise, even if it involves including some more experimental features. If it’s quiet out there, perhaps the team has time to make everything perfect. If the competitor is more reliable than you, then your team definitely needs to make everything perfect.
-
Changes In an evolving software, some things are always going to be being made to something. With infinite things that could be next up for improvement or redesign, which changes get approved or denied is one question. When release planning comes into question, though, we arrive at a more significant question; ‘when’? Does this change that redesigns the interface need to be in this release, or two down the line? By balancing the benefits, costs, and timeline, each change must be weighed against the value of having it in this release vs hanging on to it for a future one. Either decision could be the wrong one.
-
Build speed Large softwares have one thing in common; nothing gets done quickly. This factors into the idea of doing builds early, and being careful with what goes into them; taking one’s time on a build might be essential, in order to catch bugs before deployment rather than after a user has lost all their data. Alternatively, in a well-managed system that utilizes its frameworks, the build process might be fully automatable; in which case frequent builds with multiple release candidates presents itself as an option when preparing releases. It all comes down to the particulars.